【Arduino】【MCP_CAN】Seeed CAN BUS Sheild 古いライブラリ
最新のSeeed MCP CAN Shield (MCP2515) のライブラリを導入したところ下記のエラーが発生。
cannot declare variable 'CAN' to be of abstract type 'MCP_CAN'
調べたところライブラリが大きくアップデートされているようで、インポートする側のプログラムもその変更に応じた修正が必要とのこと。
https://github.com/Seeed-Studio/Seeed_Arduino_CAN/issues/106
プログラムの変更をしたくない場合は下記から古いライブラリが入手可能。
https://github.com/Seeed-Studio/Seeed_Arduino_CAN/tree/old
【wxPython】長いTextCtrlの中身の末尾を表示する方法
ファイルのパスなどを短いTextCtrlに表示する時など、ファイル名が表示されるように右揃え?にしたい場合。下記のようにTextCtrlのstyleで右揃えを指定しますが、TextCtrlを操作した後などに無効になっていることがある。
![]()
![]()
この場合はTextCtrl内のテキストを全選択することで右揃えを再度有効にすることが出来る。
m_textCtrl.SetSelection(-2, -1)

畳み込み積分の確認
畳み込み積分がいまいちイメージしづらかったので実際にプログラムを書いて確認してみた。
畳み込み積分の式

伝達関数
1自由度振動系にt=0でインパルス入力した応答を伝達関数として使う。
インパルス入力は周波数領域で全周波数で大きさ1のスペクトルを持つので、インパルス応答の周波数スペクトルがそのまま伝達関数となる性質を使う。
減衰しながら振動が収束する系。

入力
t<1までは0で1<=tで1となるステップ入力。インパルス入力がずっと続く入力とみなせる。

出力(畳み込み積分)
畳み込み積分によって最初の図のような応答を示す系に入力を入れた際の時系列の応答が求まった。ステップ入力を入れた瞬間オーバーシュートして、振動しながら一定値に収束するのでイメージ通り。

例えばt=2.0sec時点の出力はt=2.0での入力と、t=1.0からステップ入力を入れた出力の名残りの影響を受けていて、それはt=2.0secまでの畳み込み積分で求まる。
イメージとしては入力波形の時間軸を左右ひっくり返して、応答と入力の内積をとる感じが個人的にしっくりくる。

使ったコードはこちら
dt = 0.05 time = np.arange(0, 5, dt) m = 400 # [kg] omega = 2 * np.pi * 1.5 zeta = 0.2 sigma = omega * zeta # ----- 粘性1自由度振動系 インパルス入力の応答 h = np.exp(-sigma * time) * np.sin(omega * time) / (m * omega) # ----- 0<=t<1まで0で 1<=t<=5まで1が続くステップ入力(インパルスが連続している状態) f = np.hstack([np.zeros(int(1 /dt)), np.ones(int((5 -1 + dt) / dt))]) # ----- ステップ入力と粘性1自由度振動系の畳み込み積分 y = np.zeros(time.shape[0]) for t in range(time.shape[0]): for tau in range(t+1): y[t] = y[t] + f[tau] * h[t - tau] # ----- グラフ化 fig, ax = plt.subplots(3, 1, gridspec_kw=dict(hspace=0.4), figsize=(5, 6)) ax[0].plot(time, h) ax[0].set_xlabel("Time[sec]") ax[1].plot(time, f) ax[1].set_xlabel("Time[sec]") ax[2].plot(time, y) ax[2].set_xlabel("Time[sec]")
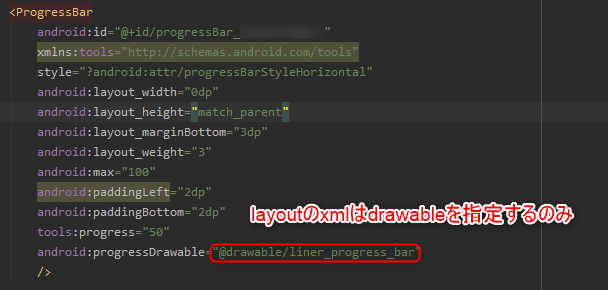
【Android】バータイプのインジケータ -> ProgressBarクラスの応用
以前書いた円形のプログレスバーで値に応じで色をグラデーションさせる方法のバータイプのプログレスバーへの応用。
oregengo.hatenablog.com
設定は全てxml側で完結できて、
Layout

【Android】apkをadb経由でインストールする際のトラブルシュート
apkでAndroidのアプリを配布する場合,gmailでは.apkが添付できなかったので仕方なくadbのコマンドでインストール.
その際,すんなりいかなかったのでハマりポイントの覚え書き.
インストールは
adb install -r (apkのパス)
うまくいかない場合は下記を試す.
- ファイル転送モードでPCとつながっているか確認
- apkをReleaseで作成して,すでに端末にデバッグした際にアプリがインストールされている場合はエラーが出る.→以前のアプリを一度アンインストール
- 端末がunauthrizedと出てインストールできない場合 → C:\Users\***\.android下にある adbkeyとadbkey.pubファイルを削除.その後 adb kill-server とadb start-serverを実行
こちらを参考にさせて頂きました.
blog.abars.biz
blog.integrityworks.co.jp
【Arduino】Hexでの配布とFlash方法
ArduinoのプログラムをHexで配布し,Flashするまでの備忘録.
- Arduinoのメニューから”コンパイルしたバイナリを出力”を選択.スケッチと同じフォルダにHexファイルが生成される.
- avrdude.exeのパスを調べておく.パスを通しておいた方が便利かも.e.g.)C:\Program Files (x86)\Arduino\hardware\tools\avr\bin
- avrdude.confのパスを調べておく.e.g.)C:\Program Files (x86)\Arduino\hardware\tools\avr\etc\avrdude.conf
- ボードの書き込み時に使われるポートを調べておく.Microの場合はリセットボタン2回押しで書き込みモードに入る.その際にポートが変化するのでデバイスマネージャから確認する.
- 下記をコマンドプロンプトから実行(Microの場合),.大文字と小文字は区別されるので注意
avrdude -C(avrdude.confのパス) -v -patmega32u4 -cavr109 -PCOM*(書き込みモード時のポート番号) -b57600 -D -Uflash:w:(Hexのパス):i
コマンドはArduino IDEの環境設定→ より詳細な情報を表示する:書き込み にチェックを入れてFlashすると Arduino IDEがavrdudeに渡すコマンドが表示できるのでそれを参考にした.
こちらを参考にさせて頂きました.
試行錯誤な日々: avrdudeでleonardo(ATmega32U4)にUSBシリアル経由でelfファイルを書き込むには、ブートローダーを書き込みモードにしておく必要がある
Arduino (Leonardo互換)のHEX書き込み - kuroの覚え書き
【Android,Java】メソッドの呼び出し元の確認
実行中のメソッドがどこから呼ばれているかチェックする方法.
StackTraceElement ste = Thread.currentThread().getStackTrace()[3];
これにより「クラス名」「メソッド名」「行数」が確認可能.
こちらを参考にさせて頂きました.
accelebiz.hatenablog.com